Regression with multiple predictors
Lecture 7
A simple example
Let’s examine the first quarter of 2020 high prices of Microsoft, IBM, and Apple stocks to illustrate some ideas.
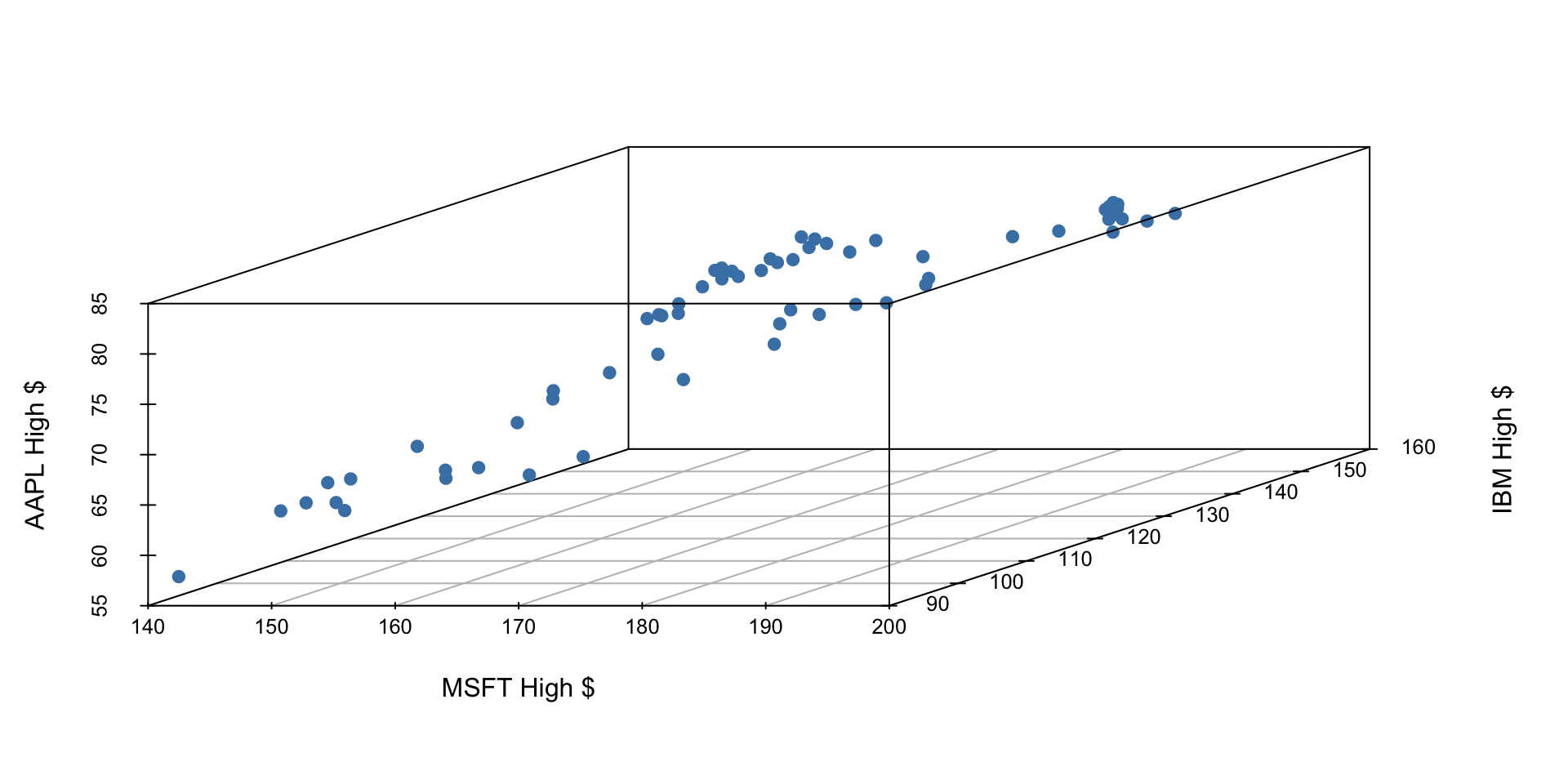
If we have three measurements (variables) then each observation is a point in three-dimensional space. In this example, we can choose one of our measurements to be the outcome variable (e.g. Apple stock price) and use our other two measurements (MSFT and IBM price) as predictors.
In general, the total number of measurements, i.e. variables (columns) in our linear model represents the spatial dimension of our model.
2 predictors + 1 outcome = 3 dimensions
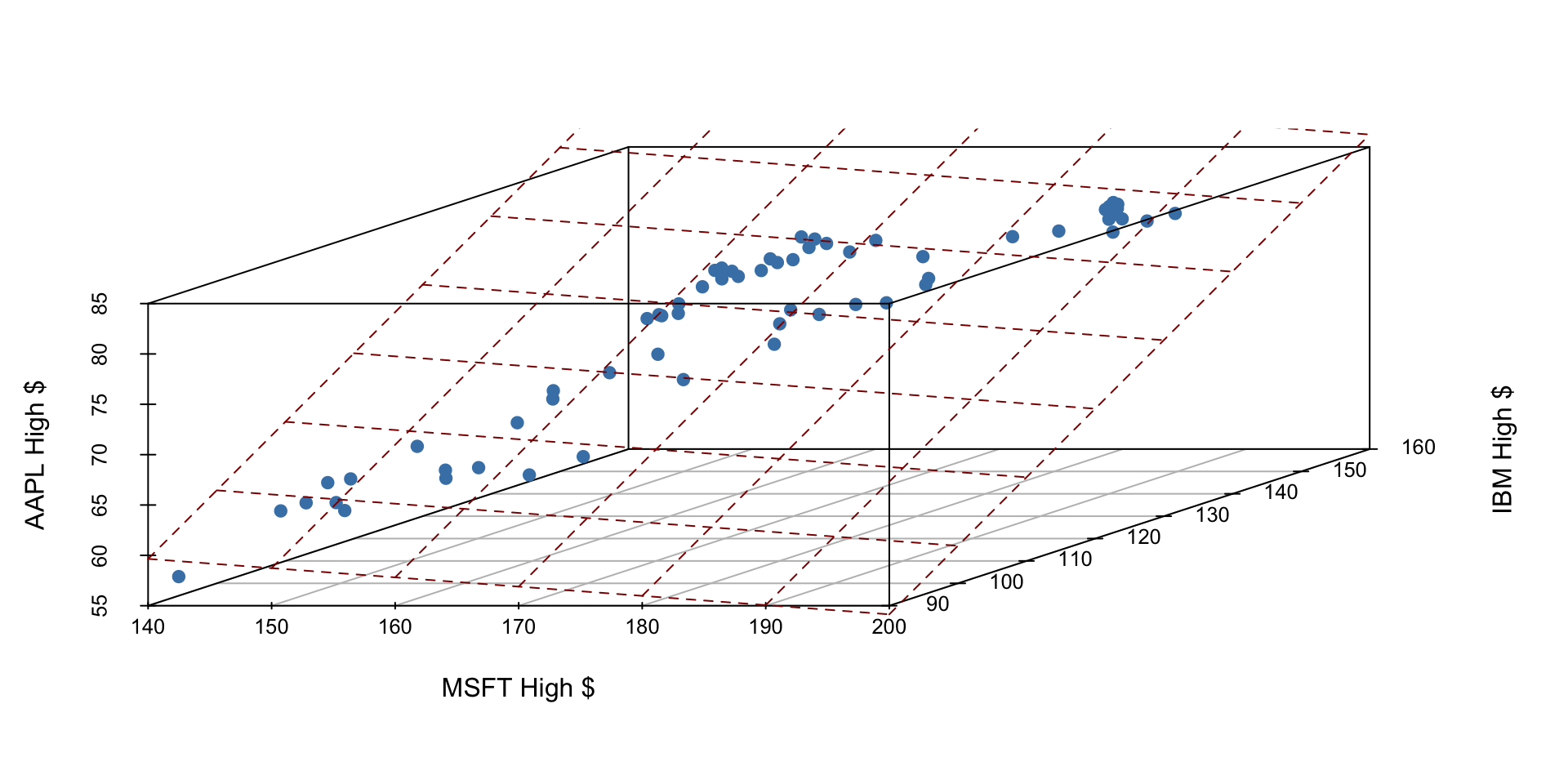
The fitted linear model no longer looks like a line, but instead looks like a plane. It shows our prediction of AAPL price (\(y\)) given both MSFT price (\(x_1\)) and IBM price (\(x_2\)).
Application exercise
Go to Posit Cloud and start the project titled ae-07-Books.
ICYMI
Today’s daily check-in access code: ___ (released in class)
![]()