Inference two means
Lecture 21
Case study: Birth weights of babies and smoking
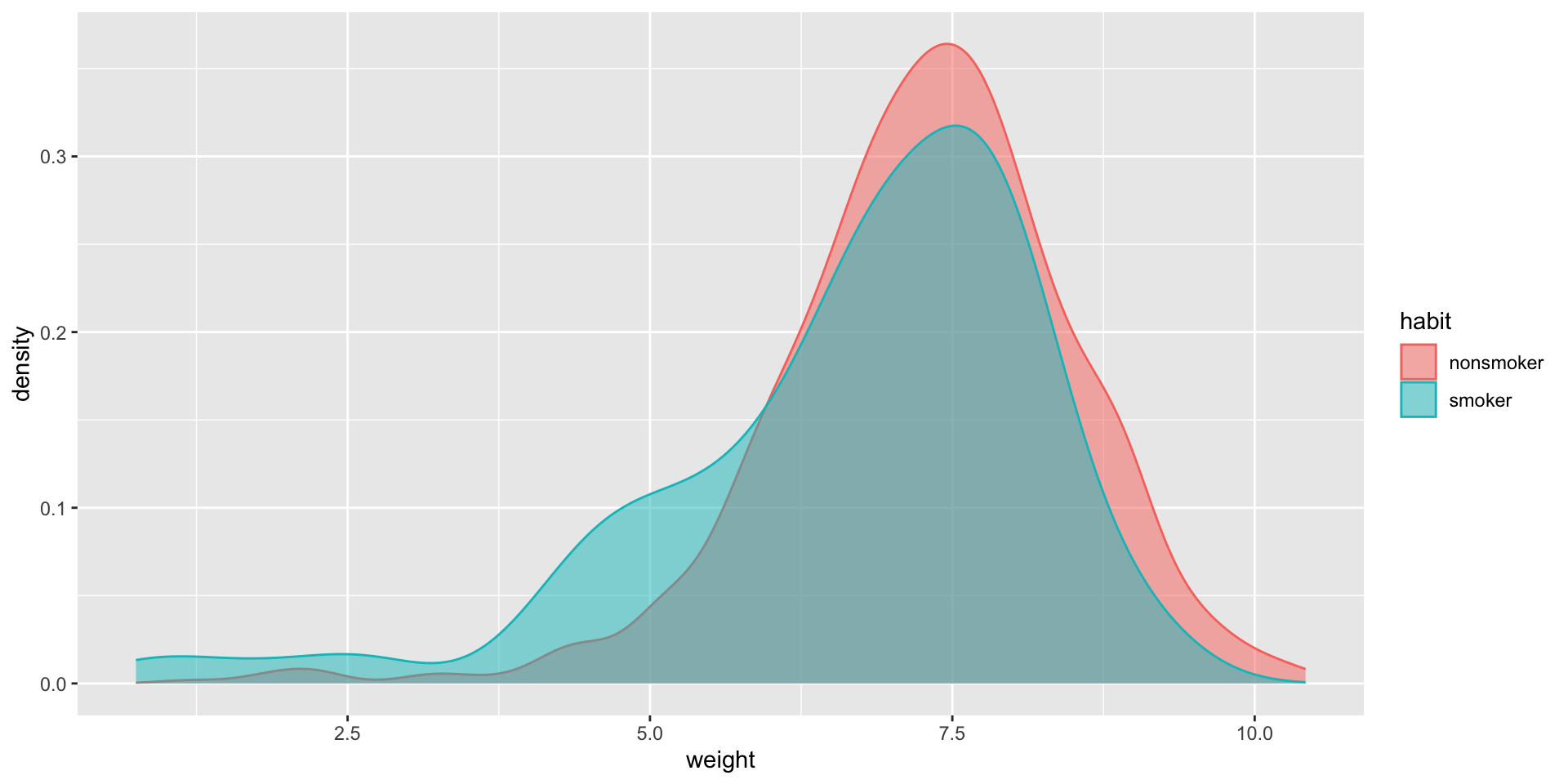
Every year, the United States Department of Health and Human Services releases to the public a large dataset containing information on births recorded in the country. This dataset has been of interest to medical researchers who are studying the relation between habits and practices of expectant mothers and the birth of their children. In this case study we work with a random sample of 1,000 cases from the dataset released in 2014. The distributions of birth weights of babies, measured in pounds, by mother’s smoking habit are shown below.
Application exercise
Go to Posit Cloud and continue the project titled ae-16-Birth weights.
![]()